
TabTransformer Keras Implementation
Date of writing: 30.8.2022
During my internship at Arute Solutions in July and August 2021, I undertook a two-stage project focusing on enhancing features for a time series dataset. Initially, I concentrated on engineering features in the first stage. Transitioning into the second stage, my focus shifted towards the realm of deep learning. Despite having completed courses from the Deep Learning Specialization by DeepLearning.AI, I had yet to apply deep learning techniques to time series data.
In my pursuit of acclimating to deep learning methodologies for time series data and developing my own Keras model, I commenced by constructing an RNN model using Keras. The insights gained from this experience proved invaluable when tackling the subsequent task, which involved implementing and utilizing a TabTransformer model in Keras.
Within this document, I aim to showcase the RNN module I crafted and delve into the intricacies of the TabTransformer. A source of personal pride is my work on the TabTransformer, now my most appreciated repository on GitHub. Furthermore, this repository has been featured in the code examples of the “Modern Deep Learning for Tabular Data” textbook authored by Andre Ye and Zian Wang, as evidenced by its inclusion in their corresponding code repository.
RNN Implementation
The RNN implementation is available on my Github, under the repository I created for tracking my progress in my intership. You can also see the RNN code below:
class RNN(tf.Module):
def __init__(self, state_size, batch_size, **kwargs):
super().__init__(**kwargs)
# for calculating the next state
self.w1 = tf.Variable(np.random.rand(state_size + 1, state_size), dtype=tf.float64)
self.b1 = tf.Variable(np.random.rand(1), dtype=tf.float64)
# for calculating output
self.w2 = tf.Variable(np.random.rand(state_size, 1), dtype=tf.float64)
self.b2 = tf.Variable(np.random.rand(1), dtype=tf.float64)
self.states = tf.Variable(np.zeros((batch_size, state_size)), shape=(batch_size, state_size))
# calculate output from current state
# calcualte next state from current state + input
# input shap: [batch_size, 1]
def __call__(self, x):
input_state_stacked = tf.concat([x, self.states], axis=1)
output = tf.matmul(self.states, self.w2) + self.b2
self.states = tf.tanh(tf.matmul(input_state_stacked, self.w1) + self.b1)
return tf.sigmoid(output)
def run_batch(self, batch):
y_preds = []
for i in range(batch.shape[1]):
y_preds.append(self(batch[:, i, None]))
return tf.concat(y_preds, axis=1)
def __str__(self):
return " ".join([str(i) for i in self.state.numpy()])
I then added a method for training the model and a training loop:
# x: batch of sequences (batch_size, sequence length)
def train(model, batch, y_actual, learning_rate):
with tf.GradientTape() as tape:
y_pred = model.run_batch(batch)
current_loss = tf.reduce_mean(tf.square(y_pred - y_actual))
d_w1, d_b1, d_w2, d_b2 = tape.gradient(current_loss, [model.w1, model.b1, model.w2, model.b2])
model.w1.assign_sub(learning_rate * d_w1)
model.b1.assign_sub(learning_rate * d_b1)
model.w2.assign_sub(learning_rate * d_w2)
model.b2.assign_sub(learning_rate * d_b2)
return current_loss.numpy()
# Define a training loop
def training_loop(model, x, y, epochs, learning_rate, print_every = 1, split=0.2):
split_index = int(x.shape[0] * split)
x_train = x[split_index:]
y_train = y[split_index:]
x_test = x[:split_index]
y_test = y[:split_index]
train_losses = []
test_losses = []
for epoch in range(epochs):
batch_train_losses = []
batch_test_losses = []
for batch in range(x_train.shape[0]):
# Update the model with the single giant batch
train_loss = train(model, x_train[batch], y_train[batch], learning_rate)
batch_train_losses.append(train_loss)
for batch in range(x_test.shape[0]):
y_pred = model.run_batch(x_test[batch])
batch_test_losses.append(np.mean((y_pred - y_test[batch])**2))
loss_average = lambda l: sum(l)/len(l)
epoch_train_loss = loss_average(batch_train_losses)
train_losses.append(epoch_train_loss)
epoch_test_loss = loss_average(batch_test_losses)
test_losses.append(epoch_test_loss)
if epoch%print_every == 0 or epoch == epochs-1:
print("Epoch %d: train loss=%.5f, test loss=%.5f" % (epoch, epoch_train_loss, epoch_test_loss))
return train_losses, test_losses
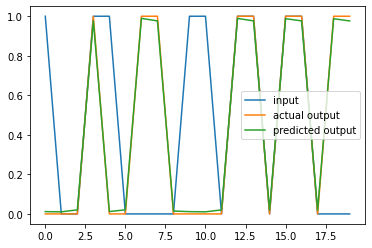
I was able to train an instance of my RNN implementation to model a delayed signal:
TabTransformer
Once I was satisfied with the RNN, I began working on the TabTransformer model. The Tabtransformer model was an attempt to harness the power of transformers in tabular data. Data followed two paths:
- Continuous features were normalized
- Categorical features were embedded and then fed to a stack of transformers, generating contextual embeddings.
Finally, these two paths are merged and fed to an MLP.
The architecture is illustrated in the following figure from the paper:
![]()
I used the paper and a PyTorch implementation of the TabTransformer to implement a TabTransformer in Keras. My code is available in a repository on my GitHub. You can also see the code and the architecture below:
![]()
from tensorflow import keras
from tensorflow.keras import layers
class TransformerBlock(layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
# parametreleri
self.att = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.ffn = keras.Sequential(
[layers.Dense(ff_dim, activation="relu"), layers.Dense(embed_dim),]
)
# batch-layer
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
class TabTransformer(keras.Model):
def __init__(self,
categories,
num_continuous,
dim,
dim_out,
depth,
heads,
attn_dropout,
ff_dropout,
mlp_hidden,
normalize_continuous = True):
"""TabTrasformer model constructor
Args:
categories (:obj:`list`): list of integers denoting the number of
classes for a categorical feature.
num_continuous (int): number of categorical features
dim (int): dimension of each embedding layer output, also transformer dimension
dim_out (int): output dimension of the model
depth (int): number of transformers to stack
heads (int): number of attention heads
attn_dropout (float): dropout to use in attention layer of transformers
ff_dropout (float): dropout to use in feed-forward layer of transformers
mlp_hidden (:obj:`list`): list of tuples, indicating the size of the mlp layers and
their activation functions
normalize_continuous (boolean, optional): whether the continuous features are normalized
before MLP layers, True by default
"""
super(TabTransformer, self).__init__()
# --> continuous inputs
self.normalize_continuous = normalize_continuous
if normalize_continuous:
self.continuous_normalization = layers.LayerNormalization()
# --> categorical inputs
# embedding
self.embedding_layers = []
for number_of_classes in categories:
self.embedding_layers.append(layers.Embedding(input_dim = number_of_classes, output_dim = dim))
# concatenation
self.embedded_concatenation = layers.Concatenate(axis=1)
# adding transformers
self.transformers = []
for _ in range(depth):
self.transformers.append(TransformerBlock(dim, heads, dim))
self.flatten_transformer_output = layers.Flatten()
# --> MLP
self.pre_mlp_concatenation = layers.Concatenate()
# mlp layers
self.mlp_layers = []
for size, activation in mlp_hidden:
self.mlp_layers.append(layers.Dense(size, activation=activation))
self.output_layer = layers.Dense(dim_out)
def call(self, inputs):
continuous_inputs = inputs[0]
categorical_inputs = inputs[1:]
# --> continuous
if self.normalize_continuous:
continuous_inputs = self.continuous_normalization(continuous_inputs)
# --> categorical
embedding_outputs = []
for categorical_input, embedding_layer in zip(categorical_inputs, self.embedding_layers):
embedding_outputs.append(embedding_layer(categorical_input))
categorical_inputs = self.embedded_concatenation(embedding_outputs)
for transformer in self.transformers:
categorical_inputs = transformer(categorical_inputs)
contextual_embedding = self.flatten_transformer_output(categorical_inputs)
# --> MLP
mlp_input = self.pre_mlp_concatenation([continuous_inputs, contextual_embedding])
for mlp_layer in self.mlp_layers:
mlp_input = mlp_layer(mlp_input)
return self.output_layer(mlp_input)
Conclusion
I tested the TabTransformer model and compared the results with tree based methods such as LGBM and XGBoost and found comperable results. One issue with the TabTransformer model was that it took too long to train. But instead of training a model from scratch like in tree based methods, it is possible to re-train a trained TabTransformer model.
The model I wrote was used in the company and integrated to a collection of models used in the company. It was also used as code examples of the textbook “Modern Deep Learning for Tabular Data “ textbook